
這篇文章算是近期的 AI 學習筆記,因此它沒有真正意義上的結論,試著用口語的數學去解釋:
當我們請 AI 把「我肚子餓了」翻譯成英文,究竟發生了什麼?
在文章開始前,有一件事情必須先被強調:
“我們”是存在在這個宇宙中的一個物理世界。
當人講出「我肚子餓了」,宇宙之中便多了一串聲音(音波);如果是打字,那宇宙中多的則是一串文字的光學形態。
這兩者都是「物理世界中的事件」。
一、物理世界的中文透過 AI 變成英文,這整個過程到底發生了什麼?
1-1. 物體 → 向量(vector)
先一起做一個小小的「正念」練習。
當我們說「我」的時候,這個「我」在宇宙中具有位置:
(x,y,z)這是一個向量。
如果加入速度:
(x,y,z,vx,vy,vz)這仍然是一個向量。
你在宇宙中的狀態可以被描述成向量,
而一個物體、聲音、影像、甚至一個句子,
同樣可以被壓縮成某種形式的向量。
一張 100×100 的灰階圖片可以展平成 10,000 維向量:
I=(p1,p2,...,p10000)真實物體 → 光線 → 相機感光 → 像素 → 向量。
換句話說:
- 物體的狀態是向量
- 文字的狀態也是向量
- 語意的狀態也必須是向量
AI 的第一步,就是把「物理世界的事件」轉成向量。
於是「我肚子餓了」會被切成一串 token:
「我」、「肚子」、「餓」、「了」
每一個 token 都被映射到一個向量,
就像宇宙中的每顆粒子都擁有自己的坐標。
1-2. 用矩陣描述「關係」
在數學裡,向量描述「狀態」,
矩陣則描述「狀態如何變化」。
平移是一個矩陣。
旋轉是一個矩陣。
縮放是一個矩陣。
我們可以把「原點」的位置換掉,也就是把: (x,y)
變成:
(x + a, y + b)也可以把把 2D 位址 (x,y) 變成 3 維:
(x,y)→(x,y,1)這時平移可以寫成「矩陣」:
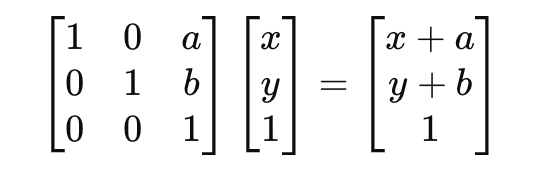
所以 AI 想理解一句話時,做的並不是「逐字思考」,而是把整串向量輸入到許多層的矩陣變換當中。矩陣讓語意得以移動、重組、壓縮、濃縮與抽取。
GPU擅長做矩陣的運算。我不擅長。
語意概念在後面會解釋,先當成是一個宇宙粒子(x,y,z)。
1-3. 物理世界 → 向量 → 矩陣
把前面兩件事合起來看,AI 翻譯的入口是:
物理世界的事件 → 向量序列
而真正的運算是:
向量序列 → 矩陣變換(超多層)→ 新的向量序列
這就是 AI 的語言理解。
二、語意的宇宙(空間)
當向量進入模型之後,它落在一個「語意空間」裡。語意空間不是地圖,也不是樹狀分類,而是一個別於物理宇宙的
看不見但具體存在的高維宇宙:
每一個詞、句子、概念,都會變成一個點(向量),
語義相似的點會聚在一起。
語義不同的點會遠離彼此。
這個宇宙的形狀,是被訓練集的統計規律決定的:
- 出現在類似語境中的詞會靠在一起
- 表現相反語意的詞會被推開
- 抽象概念會形成自己的角落
- 動物、情緒、食物、科技詞彙,各自聚成群落
想像你把所有「動物」做成 2D 空間:
- X 軸:大小
- Y 軸:兇猛程度
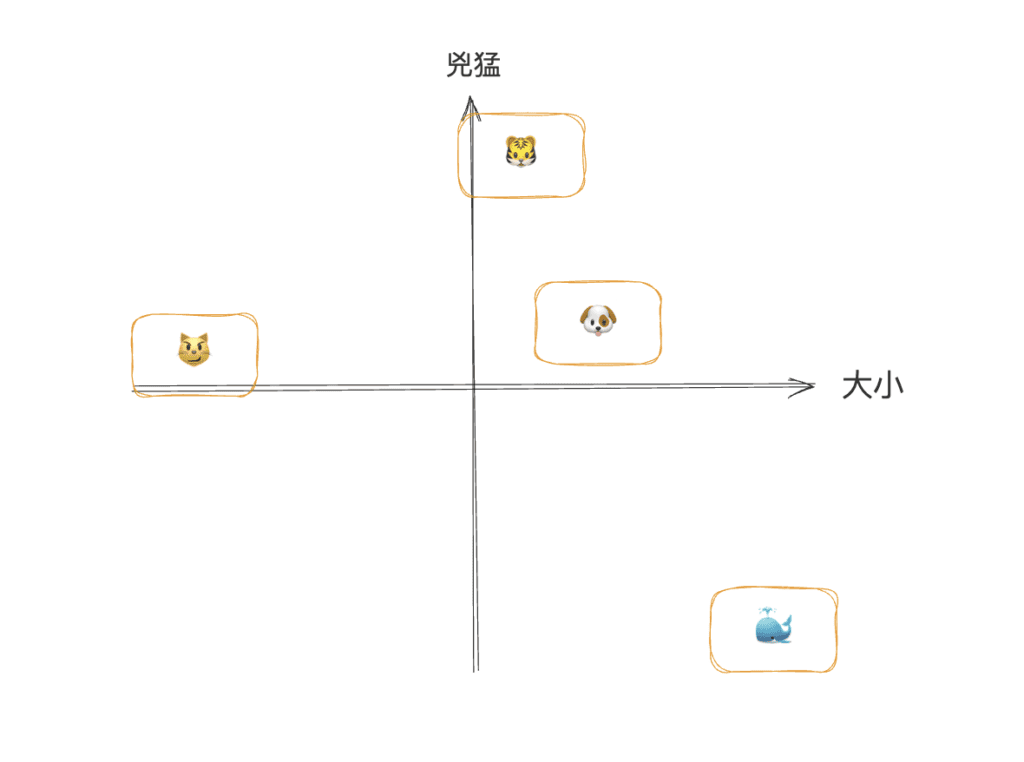
雖然只是 2D,但你已經看出語意空間的核心:
- 位置=語意
- 距離=相似度
- 方向=語意變化
這就是語意空間的概念。
2-1. 真的語意空間不是 2D,而是 768 維、1536 維、4096 維…
如BERT模型是用 768 維度的 embedding,也就是:這 768 個方向代表 768 種語意特徵。每個詞
不只是 (x, y),而是 (x₁, x₂, x₃, … x₇₆₈)
例子:「貓」的向量可能是:
[−0.21, 0.88, −0.55, …, 0.09]
而「狗」的向量是:
[−0.18, 0.92, −0.50, …, 0.07]
它們距離很近 → 語意接近。
2-2. 語意空間是怎麼形成的?
語意空間不是人設計的,是模型「學出來的」。本質上是一個由統計規律形成的「自然語言地形圖」。訓練句子時:
- 「貓」常和「咪咪叫」「可愛」「四條腿」一起出現
- 「狗」常和「汪汪叫」「寵物」「四條腿」一起出現
- 「樹」不會跟上面那些詞一起出現
模型為了壓縮語言規律,會把語意相似的東西擠在一起、不同的東西推開。
2.3 語意空間的幾何性質
在語意空間中,加法、減法都有語意,是可以做運算的:
向量(國王)− 向量(男人)+向量(女人)≈ 向量(女王)i. 語意是可幾何化的,性別是一個「方向」,皇室是一個「方向」。
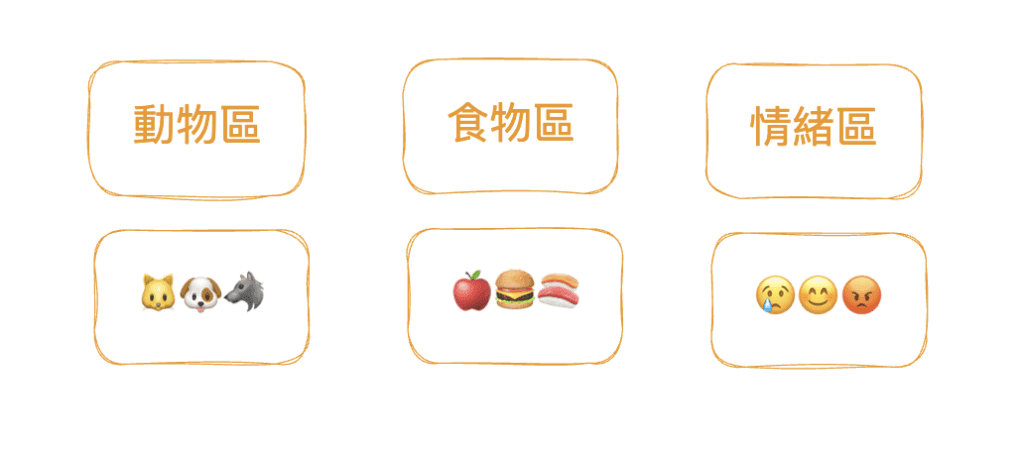
ii. 語意叢集(clusters)
在語意空間中:
地名又是一群
動物會聚在一起
食物一群
情緒詞一群
III. 語意是可量測的
兩個向量越接近,語意越相似:
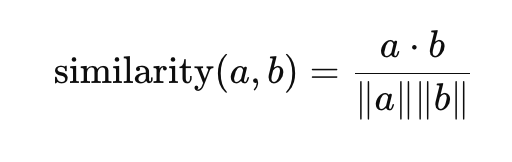
- sim(“餓”, “肚子餓”) ≈ 0.95
- sim(“餓”, “飽”) ≈ – 0.3
- sim(“餓”, “快樂”) ≈ 0.0
語意被數學化了。
本質上,語意空間就是一個由統計規律構成的高維幾何宇宙,其距離、方向、角度都代表語意關係。
順帶一提:
如果訓練集裡不存在某個資訊,這個語意宇宙就沒有那個點。
比如現實世界 John 的體重 69 公斤。
模型的語意空間裡的 John 只有一個模糊位置,而這個位置與「體重」的關係是統計性的,所以模型會給出一個它語意空間中「最可能的體重」,像是 65。
這也是為什麼有時候你會覺的AI在答非所問的原因。
三、物理世界的中文 → 英文轉換軌跡
於是整個翻譯過程,數學面向會長這樣:
- 中文句子被拆成 token
- 每個 token 變成一個高維向量
- 這些向量被送入多層矩陣運算
- 運算結果是一組「壓縮後的語意向量」
- 語意向量再透過另一組矩陣被映射成英文 token
- 英文 token 再回到物理世界的文字版「I am hungry」
物理世界(聲音/文字)
→ 數字 → 向量 → 矩陣運算 → 新的向量 → 數字 → 英文字串(再回到物理世界)
3-1. 中文 → 數字
原本你說的中文句子:我肚子餓了
在物理世界是:一串聲音(音波)
或一串文字(字形),電腦無法直接理解這些東西。所以第一步是:把每個詞轉成「向量」。
例:
中文詞 -> 向量(embedding 範例)
我 -> [-0.21, 0.87, …, 0.03]
肚子 -> [0.11, -0.32, …, 0.77]
餓 -> [1.22, 0.09, …, -0.44]
了 -> [0.05, -0.10, …, 0.02]
可以想成是 把中文詞語壓縮成 768 維(或 1536、4096…)的數字座標
(像是把語意放進某個空間)
3-2. 語意推理(大量矩陣運算)
此時模型內部做的是:
向量序列 → 多層 Transformer(全是矩陣運算) → 新的向量序列
一層 Transformer 做三件事:
1️⃣ 線性變換(矩陣乘法)
2️⃣ 注意力(也是矩陣)
3️⃣ 前饋網路(MLP — 兩次矩陣乘法)
經過 24 層、48 層甚至 100+ 層後
模型形成一個新的語意向量:
Vmeaning
=f([我,肚子,餓,了])這是模型理解後的「意思」。像是:
“我現在處於飢餓狀態” 的語意向量。
數學公式就不列了,Transformer的逐步概念會放在最後面。
3-3. 語意向量 → 英文單詞(產生英文)
模型先預測下一個英文 token:
例如它得到一個向量 h:
h = [0.22,−0.51,…,1.07]
然後用「輸出矩陣」做分類:
logits = hWvocab
hWvocab 是大小 =
(hidden_size × 詞彙量) 的巨型矩(例:4096 × 50,000)
這一步其實就是:用矩陣推算出:最接近語意的英文單字是哪一個?
softmax 後得到:
“I” : 0.91 機率
“me” : 0.03 機率
“we” : 0.02 機率
→ 模型選 “I” ,下一步再產生:
“am”, “hungry”, “.”
3-4. 數字 → 英文文字(回到物理世界)
選到 token “hungry” 後:
- 模型這時候存的是一個index(例如詞表中的第 2831 個 token)
- 系統再把索引查表 → 變成英文字串 “hungry”
- 最後再輸出到螢幕
於是語言從數字回到現實世界:
英文句子出現了: I am hungry.
🎉 🎉 🎉 🎉 🎉 🎉 🎉
值得關注的是,
中文不是直接「被翻譯」的。
中文是被吸進模型的向量宇宙,
經過層層矩陣重組後,再在模型的語意空間中,找到最接近的英文表達方式。
四、補充在48層的 Transformer 中如何演化?
以句子:
我肚子餓了
來看「語意向量」如何在層中演化。
第 1 層(底層):捕捉字詞資訊(誰?什麼?),此時的向量還很「詞彙性」。:
「我」 → [個人]
「肚子」 → [身體]
「餓」 → [狀態]
「了」 → [完成]第 6 層:開始理解「局部語意」:
「肚子餓」 → 合併成 [生理需求]模型開始知道「肚子」+「餓」=「飢餓」。
第 12 層:跨詞語意開始形成:
「我」 + 「肚子餓了」
→ [我現在的身體狀態]第 24 層:模型理解完整含義:
→ [第一人稱、當下、生理飢餓]第 48 層(最終層):
形成語意壓縮向量,要”翻譯“成英文了:
→ [I am hungry 的語意向量]這就是翻譯真正發生的地方。
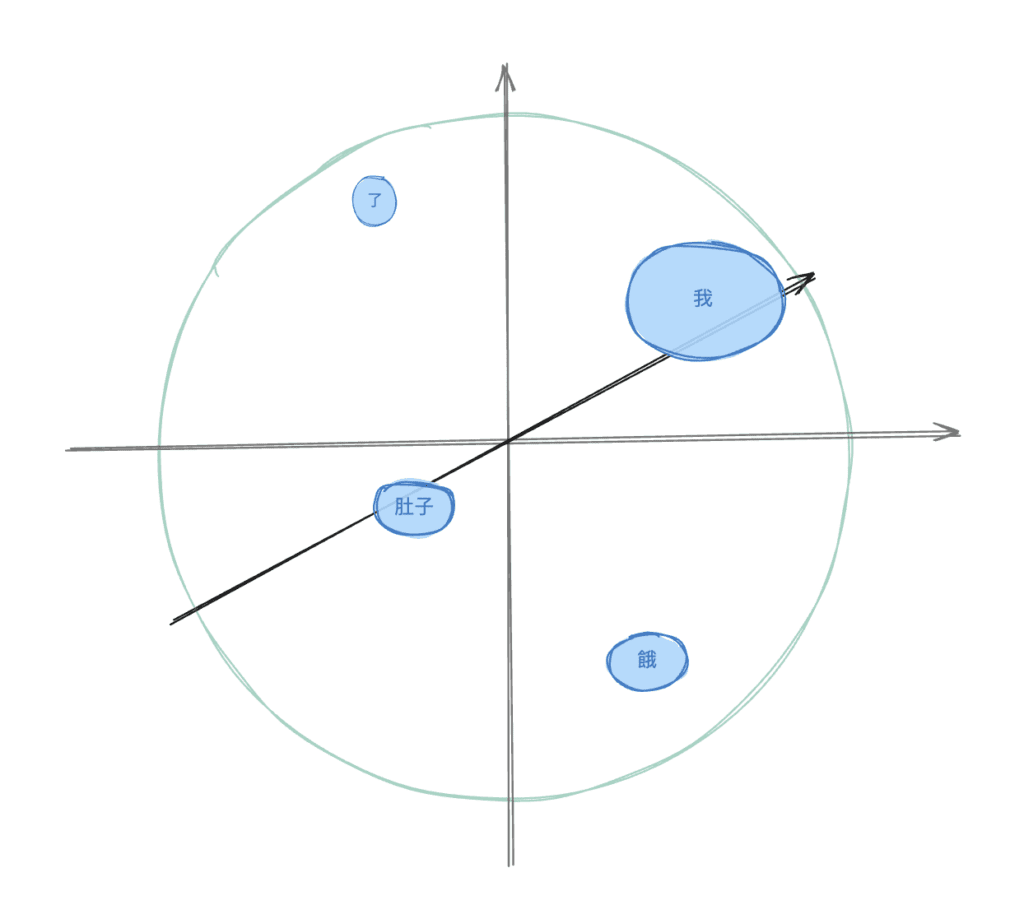
4-2.「我肚子餓了」→ “I am hungry” 的語意軌跡
語意空間中的路徑如下:
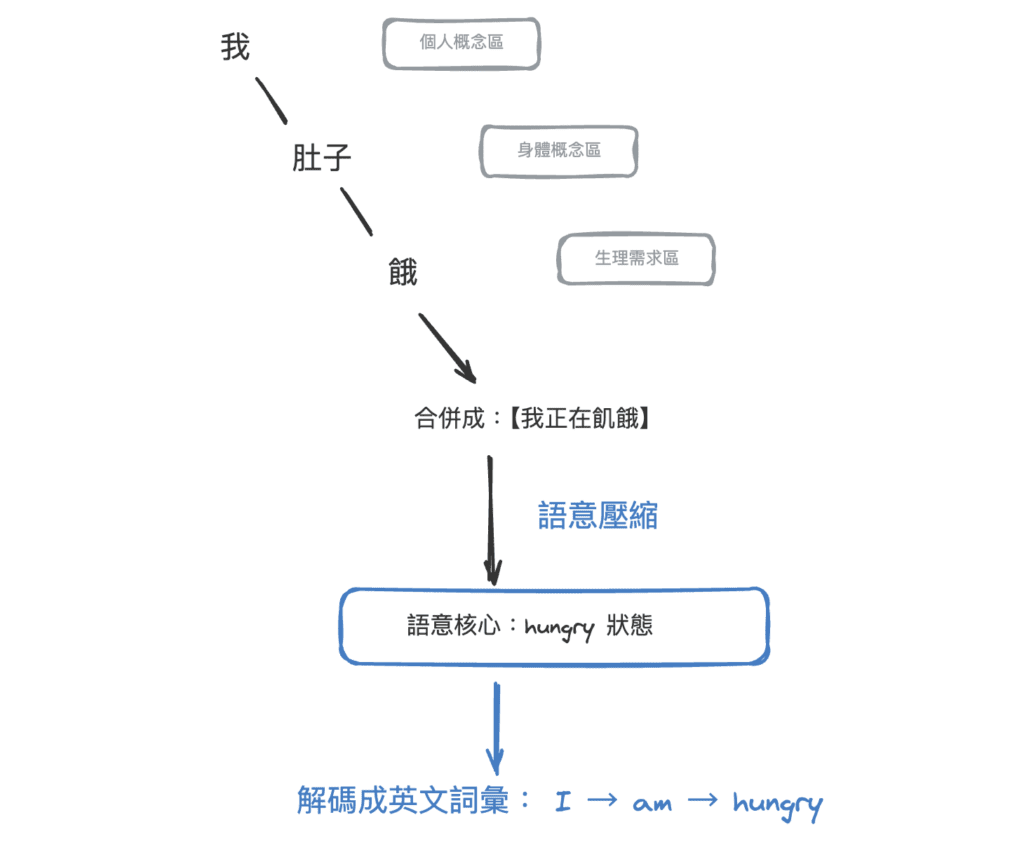
模型其實不是把中文逐字翻譯,而是:
把整句話投影到語意宇宙的某個位置,
並在那個位置選擇「最接近的英文表達」
– 2025.11.21 –
John Kuo



